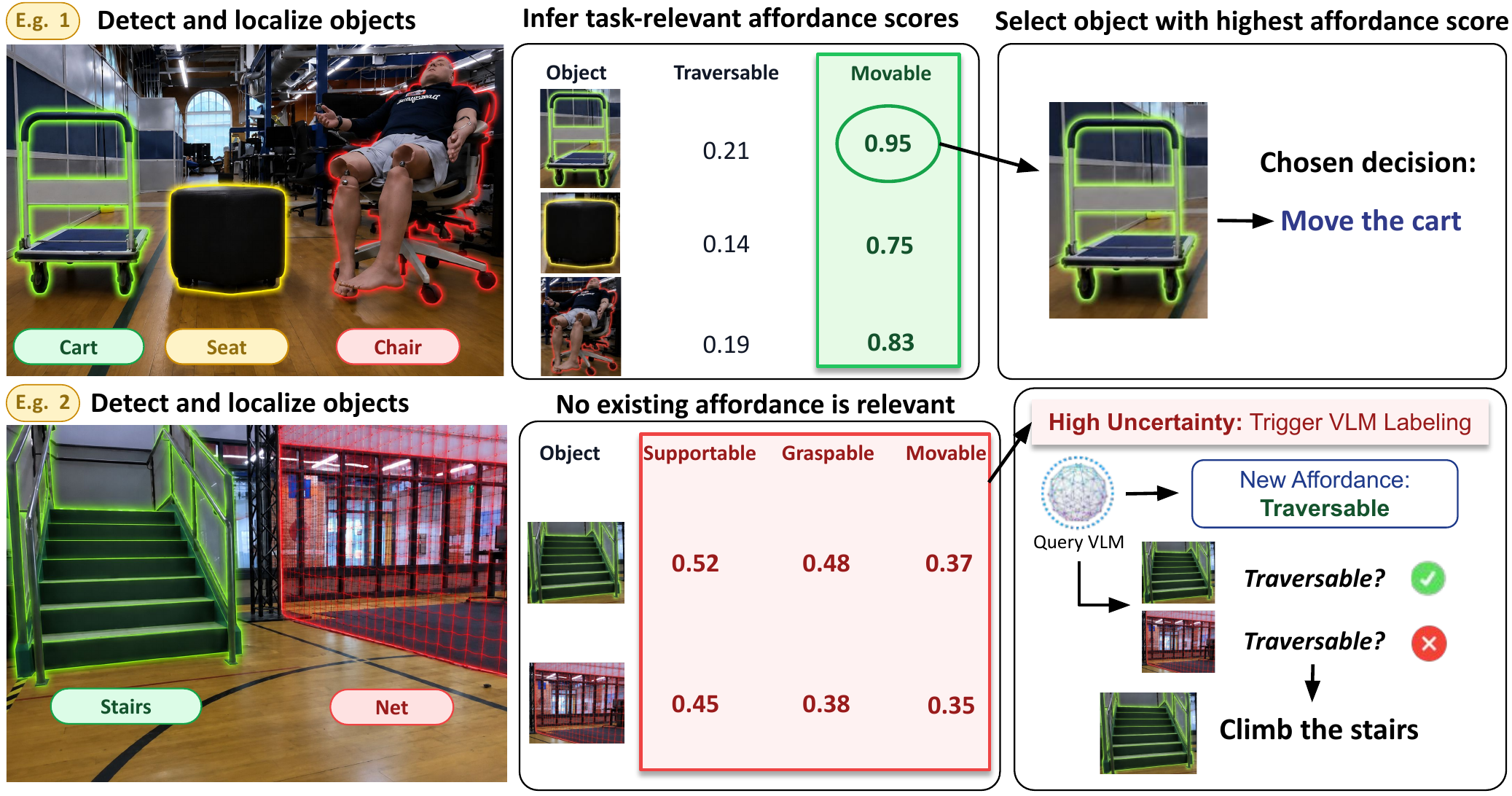
Framework Overview
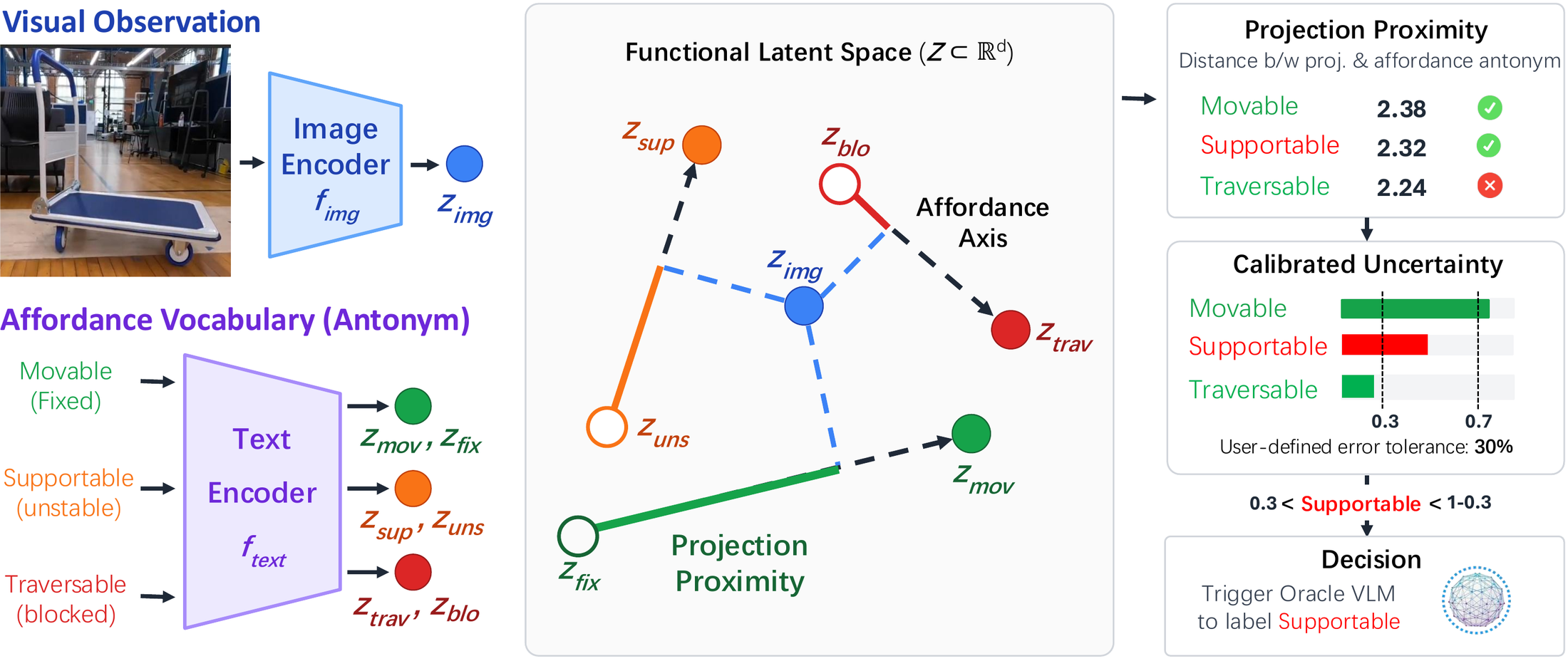
Functional Latent Space for Affordance Reasoning. A4Dance maps visual observations and affordance descriptions into a shared functional latent space. For each affordance, we construct an affordance axis between an affordance and its antonym (e.g., movable ↔ fixed). Visual observations are projected onto these axes to infer task-relevant object functionalities. Projection proximity is calibrated into uncertainty estimates, enabling the system to identify when additional reasoning is required.
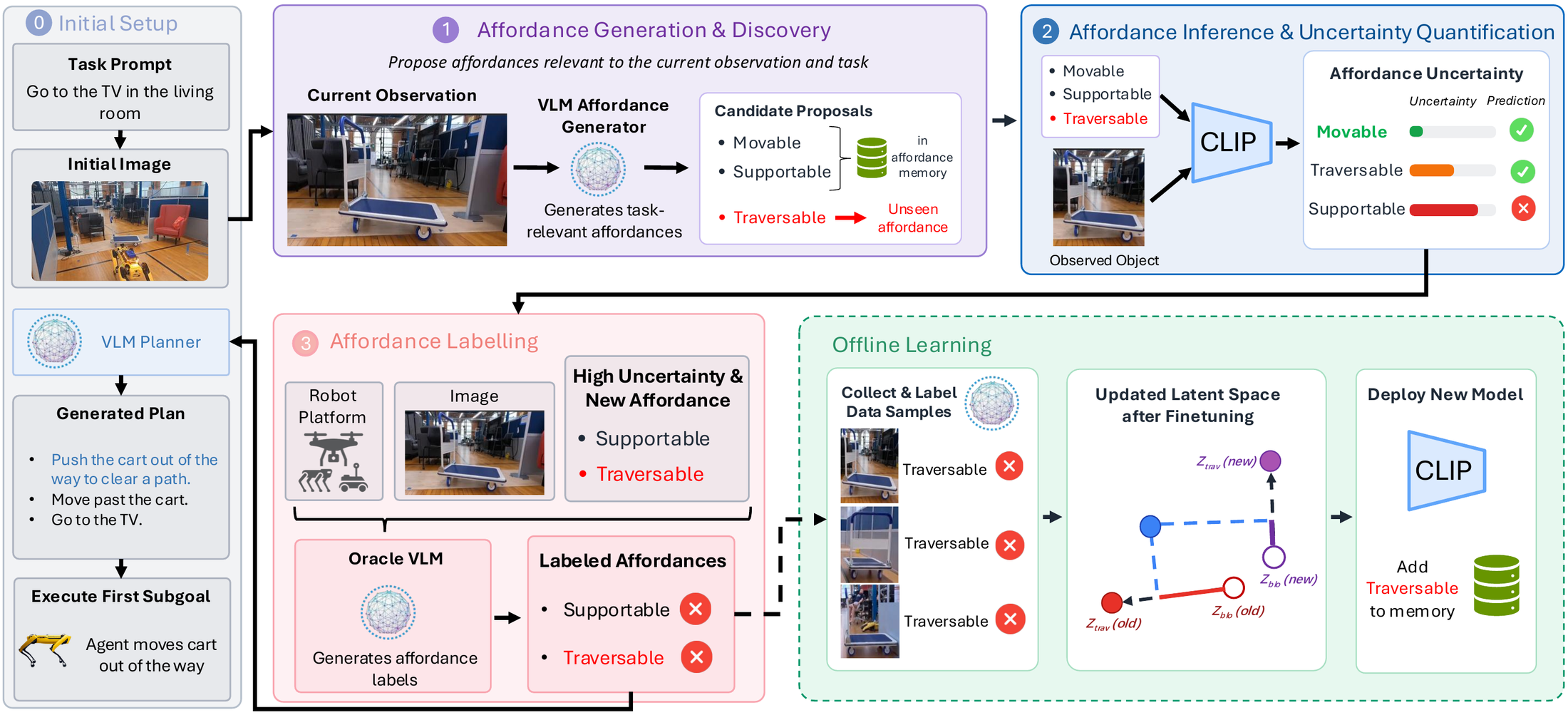
Uncertainty-Aware Affordance Discovery. Given a task and visual observation, A4Dance first generates candidate affordances relevant to the current planning problem. Affordance inference is performed in the functional latent space, while calibrated uncertainty determines whether existing affordances are sufficient. When uncertainty is high or a new functionality is required, a vision-language model proposes and labels new affordances, which are incorporated through offline learning and added to the affordance memory for future deployment.